Wstecz: 9.1 Priorytety i wiązanie W górę: 9. Operatory Dalej: 10. Konwersje niejawne, porządek
W tabeli poniżej przedstawiono operatory języka C++. W prawej kolumnie użyte są oznaczenia:
| klasa: nazwa klasy | ob: obiekt klasy |
| sklad: składowa klasy lub przestrzeni nazw | wsk: wskaźnik |
| wyr: wyrażenie | lwar: l-wartość |
| pnaz: nazwa przestrzeni nazw | typ: nazwa typu |
| naz: nazwa |
Operatory podzielone są na 18 grup — każda grupa odpowiada operatorom o tym samym priorytecie. Grupy wymienione są w kolejności od grupy operatorów o priorytecie najwyższym, w dół według malejącego priorytetu. W pierwszej kolumnie zaznaczona jest kolejność wiązania: 'R' – od prawej do lewej, 'L' – od lewej do prawej.
Dyskusję niektórych z tych operatorów, szczególnie tych związanych z klasami, konwersjami, przestrzeniami nazw i obsługą wyjątków, odłożymy do następnych rozdziałów.
Operatory te (priorytet 17 w tabeli), zapisywane są za pomocą symbolu „czterokropka” (' ::'). Operator zasięgu globalnego już znamy (patrz rozdział o zasięgu i widoczności deklaracji ). Przypomnijmy, że ::x jest nazwą globalnej zmiennej x zadeklarowanej poza wszystkimi funkcjami i klasami. Użycie „czterokropka” jest konieczne tylko wtedy, gdy nazwa (w naszym przypadku x) jest w danym bloku (funkcji) nazwą innej zmiennej, lokalnej, która wobec tego przesłoniła zmienną globalną o tej samej nazwie.
Operatory zasięgu klasy (pozycja pierwsza w tabeli) omówimy w rozdziale o klasach , a przestrzenie nazw w rozdziale o przestrzeniach nazw .
Pierwsze dwa (operator „kropka” i „strzałka”, dotyczą struktur i klas, poznamy je w rozdziale o strukturach .
Operator ' []' (indeksowania) tablicy już znamy z rozdziału o arytmetyce wskaźników .
Operator wywołania funkcji oznaczamy nawiasami okrągłymi ' ()':
func(k, m, 5)Zatem podanie nazwy funkcji z nawiasami okrągłymi powoduje wywołanie funkcji (jeśli pojawia się w instrukcji wykonywalnej, a nie w definicji lub deklaracji). Ale nie zawsze nazwa funkcji występuje z nawiasami. Czasem chcemy odnieść się do funkcji jako takiej, jako obiektu, a nie powodować jej wywołanie. W takich sytuacjach używamy nazwy funkcji bez nawiasów — ma ona wtedy interpretację wskaźnika do funkcji. Tego rodzaju wskaźniki omówimy w rozdziale o wskaźnikach funkcyjnych .
Operator konstrukcji wartości (Typ(lista_wyr)) jest nam nieznany. Ponieważ dotyczy klas, omówimy go w rozdziale o tworzeniu obiektów . Tu tylko wspomnijmy, że w C++ można konstruować obiekty typów prostych (int, double, ...) tak jakby były one obiektami jakiejś klasy. Zatem int(3) kreuje zmienną typu int i inicjuje ją wartością 3 — składnia jest wobec tego taka, jak gdybyśmy tworzyli obiekt klasy int i wysyłali wartość 3 do konstruktora (tak zwanego konstruktora kopiującego).
Przyrostkowe operatory zmniejszenia i zwiększenia (postdekrementacji i postinkrementacji) zmniejszają (zwiększają) wartość swojego argumentu (który wyjątkowo stoi po ich lewej stronie) o jeden. Czynią to jednak po obliczeniu wartości wyrażenia, w skład którego wchodzą. Tak więc po
int a = 1;
int b = a++;
wartość
a
wynosi 2, ale wartość
b
wynosi 1, bo w trakcie opracowywania drugiej instrukcji
a
miało wciąż wartość 1; zwiększenie
a
nastąpi dopiero
po zakończeniu wykonywania instrukcji przypisania.
Argumentem postinkrementacji i postdekrementacji musi zawsze być l-wartość; np.
(x+y)++nie ma sensu i jest błędne, gdyż wyrażenie (x+y) nie jest l-wartością (choć jest p-wartością). Tak więc argument operatorów postdekrementacji i postinkrementacji musi być l-wartością: ale co z rezultatem działania tego operatora na l-wartość? W Javie wartości uzyskane za pomocą tych operatorów nigdy same nie są l-wartościami. W C/C++ jest trochę inaczej: dla przyrostkowych operatorów zmniejszenia i zwiększenia wynik nie jest l-wartością, ale dla operatorów przedrostkowych wynik jest l-wartością. Dlatego
int k = 5;
int m = (++k)--;
jest prawidłowe. Wyrażenie w nawiasach jest l-wartością, bo użyty
został operator preinkrementacji; można było zatem zastosować
następnie operator postdekrementacji. Wynikiem działania tego z kolei
operatora nie jest już l-wartość, ale ponieważ użyliśmy jej
tylko po prawej stronie przypisania, więc wszystko jest w porządku.
Wartość
k
będzie oczywiście wynosić po tym
przypisaniu 5, a wartością zmiennej
m
będzie 6.
Gdybyśmy nie użyli nawiasów
int k = 5;
int m = ++k--; // ZLE !!!
kod byłby błędny: ponieważ priorytet postdekrementacji jest wyższy
niż preinkrementacji, więc najpierw obliczone byłoby wyrażenie
k-. Wynik nie byłby l-wartością — patrz
rozdział o l-wartościach —
więc podziałanie nań operatorem '
++' spowodowałoby błąd.
Warto pamiętać, że wyrażenie ++w nie jest całkowicie równoważne instrukcji w=w+1. Ta druga forma jest normalną instrukcją przypisania, a zatem najpierw zostanie obliczona wartość wyrażenia po prawej stronie, a potem lokalizacja l-wartości po lewej stronie. Zatem jeśli w jest wyrażeniem złożonym (np. zawiera wywołania funkcji), to wyrażenie to będzie obliczane dwukrotnie. Natomiast podczas opracowywania wyrażenia ++w, samo w będzie obliczane jednokrotnie. Rzadko ma to jakieś znaczenie, ale czasem zrozumienie tego może nas ustrzec przed trudno wykrywalnymi błędami.
Operator identyfikacji typu typeid pozwala na uzyskanie identyfikatora typu podczas kompilacji, a więc statycznie, jak również identyfikatora typu obiektu (ogólnie p-wartości) w czasie wykonania programu, a więc dynamicznie (RTTI; run-time type identification). Ten temat omówimy bardziej szczegółowo w rozdziale o RTTI , ale jeden przykład zastosowania tego operatora podany jest poniżej w programie sizes.cpp.
Operatory konwersji (rzutowania) pozwalają na, w miarę bezpieczną, konwersję wartości jednego typu na wartość innego typu. Ponieważ stosowanie konwersji często, choć nie zawsze, świadczy o złej konstrukcji programu i stwarza okazję do użycia błędnych lub zależnych od implementacji konstrukcji programistycznych, nadano tym operatorom celowo tak długą i niewygodną do pisania formę. Konwersje rozpatrzymy w rozdziale im poświęconym .
Pierwsze trzy z opertatorów tej grupy
dotyczą pobierania rozmiaru za pomocą operatora
sizeof.
Reultat jest typu
size_t
(który jest tożsamy z pewnym typem całkowitym
bez znaku, np.
unsigned long). Operator ten jest jednoargumentowy.
Argumentem może być nazwa typu (w nawiasie okrągłym) lub wyrażenie (nawias
jest wtedy niekonieczny) albo tak zwany pakiet. Rozpatrzmy przykład:
1. #include <iostream>
2. #include <typeinfo>
3. using namespace std;
4.
5. typedef int TABINT15[15]; ➊
6.
7. void siz(TABINT15 t1, TABINT15& t2) { ➋
8. cout << "G. t1 w siz: " << sizeof t1 << endl;
9. cout << "H. t2 w siz: " << sizeof t2 << endl;
10. }
11.
12. int main() {
13. TABINT15 tab1; ➌
14. int tab2[15]; ➍
15. int *tab3 = tab2; ➎
16.
17. if (typeid(tab1) == typeid(tab2))
18. cout << "A. Typy tab1 i tab2 takie same" << endl;
19. else
20. cout << "A. Typy tab1 i tab2 nie takie same" << endl;
21.
22. if (typeid(tab2) == typeid(tab3))
23. cout << "B. Typy tab2 i tab3 takie same" << endl;
24. else
25. cout << "B. Typy tab2 i tab3 nie takie same" << endl;
26.
27. cout << "C. TABINT15: " << sizeof(TABINT15) << endl; ➏
28. cout << "D. tab1 : " << sizeof tab1 << endl; ➐
29. cout << "E. tab2 : " << sizeof(tab2) << endl; ➑
30. cout << "F. tab3 : " << sizeof tab3 << endl; ➒
31. siz(tab2, tab2);
32. }
Wynik tego programu
A. Typy tab1 i tab2 takie same
B. Typy tab2 i tab3 nie takie same
C. TABINT15: 60
D. tab1 : 60
E. tab2 : 60
F. tab3 : 8
G. t1 w siz: 8
H. t2 w siz: 60
ilustruje warte zrozumienia własności C/C++.
Na początku dołączamy plik nagłówkowy typeinfo, aby mieć dostęp do narzędzi związanych z identyfikacją typów (patrz rozdział o RTTI ).
W linii ➊ wprowadzamy, za pomocą znanej już nam instrukcji typedef, inną nazwę typu „piętnastoelementowa tablica liczb całkowitych” (patrz rozdział o instrukcji typedef ).
Jak widać z linii ➏ i z pierwszej linii wydruku, operator sizeof prawidłowo rozpoznał rozmiar typu TABINT15. Zauważmy też, że nie można tu pominąć nawiasów, bo TABINT15 jest nazwą typu.
W liniach ➌ i ➍ definiujemy tablice tab1 i tab2 na dwa sposoby — za pomocą wprowadzonej nazwy TABINT15 i bezpośrednio. Porównując typy tych zmiennych widzimy, że rzeczywiście są one takie same (linia 'A' wydruku).
W linii ➎ definiujemy zmienną tab3 typu int* i przypisujemy do niej wartość zmiennej tab2. Przypisanie jest prawidłowe, ale nie zapominajmy, że zachodzi przy tym konwersja standardowa: typy tab2 i tab3 nie są takie same, co widzimy z linii 'B' wydruku.
W liniach ➏-➒ drukujemy rozmiary typu TABINT15 i zmiennych tab1, tab2 i tab3. Wszystkie rozmiary, za wyjątkiem tab3, wynoszą 60, co odpowiada tablicy piętnastu czterobajtowych liczb. Natomiast rozmiar tab3 jest 8, gdyż jest to zmienna typu wskaźnikowego, a nie tablicowego.
W ostatniej linii posyłamy tę samą tablicę tab2 poprzez dwa argumenty do funkcji siz. Pierwszy parametr funkcji jest typu TABINT15, więc wydawałoby się, że funkcja „wie”, że argument będzie tablicą. Drukując jednak (linia 'G' wydruku) wewnątrz funkcji rozmiar zmiennej t1, widzimy, że jest to wskaźnik o rozmiarze 8 — jest tak, gdyż przy wysyłaniu tab2 do funkcji przez wartość i tak zmienna została zrzutowana do typu wskaźnikowego (na stosie został położony adres pierwszego elementu tablicy i nic więcej).
Drugi parametr funkcji siz jest zadeklarowany jako referencja. Teraz żadnej konwersji nie ma, bo nie jest w ogóle tworzona żadna zmienna lokalna, której należałoby przypisać wartość argumentu. Wewnątrz funkcji t2 jest teraz inną nazwą dokładnie tej samej zmiennej, która w funkcji main nazywa się tab2. Zatem i informacja o typie jest ta sama i ' sizeof t2' drukuje 60 (linia 'H' wydruku).
Przedrostkowe operatory zmniejszenia i zwiększenia (predekrementacji i preinkrementacji) działają podobnie do przyrostkowych operatorów zmniejszenia i zwiększenia. Są jednak ważne różnice: operatory te zmniejszają (zwiększają) swój argument przed jego użyciem do obliczenia wartości wyrażenia, w skład którego wchodzą. Tak więc po
int a = 1;
int b = ++a;
wartość
a
wynosi 2, ale wartość
b
wynosi również 2, bo w trakcie opracowywania drugiej instrukcji
zmienna
a
została zwiększona jeszcze przed wykonaniem
przypisania. Wynikiem działania operatora preinkrementacji
lub predekrementacji jest l-wartość (pamiętamy, że tak
nie było dla
operatorów postinkrementacji lub postdekrementacji) —
tak więc wyrażenie
++++a byłoby legalne.
Operatory negacji: bitowej i logicznej omówimy poniżej razem z innymi operatorami logicznymi i bitowymi.
Operator jednoargumentowy ' +' jest właściwie operatorem identycznościowym, czyli takim, który „nic nie robi” (ang. no-op). Istnieje tylko dla wygody, aby wyrażenia typu ' k = +5' miały sens. Operatory wyłuskania adresu i dereferencji (& i *) były już omówione w rozdziale na temat typów danych .
Operatory new i delete służą do dynamicznego alokowania i zwalniania pamięci: będą omówione w rozdziale o zarządzaniu pamięcią .
Ostatni operator z tej grupy, oznaczany parą nawiasów okrągłych, to operator rzutowania. Jest on operatorem jednoargumentowym: wynikiem działania tego operatora na p-wartość pewnego typu jest odpowiadająca tej wartości p-wartość innego typu — tego wymienionego w nawiasie. Z operatora tego należy korzystać oględnie; w większości przypadków jego zastosowanie świadczy raczej o złym stylu programowania. Czasem jest jednak przydatny. Na przykład w drugiej instrukcji fragmentu
double x = 7;
int k = (int)x;
rzutowanie wartości zmiennej
x
jest wskazane,
gdyż wartość ta, jako wartość szerszego typu, może być
wpisana do zmiennej typu węższego, jakim jest typ
int, tylko ze
stratą informacji (precyzji). Choć nie jest to błąd, to kompilator
zwykle wypisuje ostrzeżenia; jeśli zastosujemy jawne rzutowanie,
ostrzeżeń nie będzie.
Rzutowanie zawsze działa na p-wartość i w wyniku daje inną p-wartość, ale nigdy l-wartość. W szczególności rzutowanie nie zmienia typu żadnej zmiennej — typu istniejącej zmiennej zmienić się nie da!
Zamiast operatora rzutowania w C++ zaleca się stosowanie bezpieczniejszych operatorów konwersji, wymienionych w tabeli w grupie odpowiadjącej priorytetowi 16. Omówimy je bardziej szczegółowo w rozdziale im poświęconym .
Należą do tej grupy dwa operatory wyboru składowej, które omówimy w rozdziałach na temat klas w C++ (rozdział o wskaźnikach na składowe ).
Wymienione w tabeli operatory arytmetyczne mają oczywiste znaczenie i ich działanie jest niemal takie samo jak w większości innych języków. Występują czasem drobne różnice: np. w Javie operator reszty '%' może mieć dowolne agumenty numeryczne, również typu double. W C/C++ operator ten wymaga argumentów typu całkowitego. Pewien kłopot mogą sprawiać wyrażenia z wartościami ujemnymi jako argumentami. Wiemy, że dzielenie liczb typu całkowitego daje w wyniku liczbę całkowitą, czyli ewentualna część ułamkowa jest obcinana. Jeśli wynik jest dodatni, to dokładna wartość ilorazu jest obcinana w dół, czyli w kierunku zera, natomiast jeśli wynik jest ujemny, to obcięcie jest w górę, a więc też w kierunku zera. Dla operatora reszty spełniona jest zawsze zasada
a = (a/b)*b + a%bdla b różnego od zera. Wynika z niej, przy założeniu, że obcinanie w dzieleniu całkowitoliczbowym jest zawsze w kierunku zera, zasada następująca: wartość
a%b jest równa co do modułu
wartości |a|%|b| i ma znak taki, jaki znak ma a
(kreski oznaczają wartość bezwzględną). Ilustruje to poniższy
programik:
1. #include <iostream>
2. using namespace std;
3.
4. int main() {
5. int i, j;
6.
7. i = 19; j = 7; cout << " 19 / 7 = " << i/j << endl;
8. i =-19; j = 7; cout << "-19 / 7 = " << i/j << endl;
9. i = 19; j =-7; cout << " 19 / -7 = " << i/j << endl;
10. i =-19; j =-7; cout << "-19 / -7 = " << i/j << endl;
11.
12. i = 19; j = 7; cout << " 19 % 7 = " << i%j << endl;
13. i =-19; j = 7; cout << "-19 % 7 = " << i%j << endl;
14. i = 19; j =-7; cout << " 19 % -7 = " << i%j << endl;
15. i =-19; j =-7; cout << "-19 % -7 = " << i%j << endl;
16. }
którego wynikiem jest
19 / 7 = 2
-19 / 7 = -2
19 / -7 = -2
-19 / -7 = 2
19 % 7 = 5
-19 % 7 = -5
19 % -7 = 5
-19 % -7 = -5
Ta zasada będzie inna, jeśli obcinanie w dzieleniu całkowitoliczbowym
jest zawsze w dół, a nie w kierunku zera (tak może sie zdarzyć dla starych
kompilatorów). Dlatego lepiej unikać stosowania operatora reszty
dla liczb ujemnych.
Operatory relacyjne (' <', ' <=', ' >', ' >=') i porównania (' ==', ' !=') mają oczywistą interpretację. Wyrażenie ' a == b' ma wartość logiczną odpowiadającą na pytanie czy wartość a jest równa wartości b. Wyrażenie ' a != b' ma wartość logiczną odpowiadającą na pytanie czy wartość a jest różna od wartości b. Argumentami mogą być dwa skalary, czyli p-wartości liczbowe, lub (choć nie zawsze) dwa adresy (wartości zmiennych wskaźnikowych lub wynik operacji wyłuskania adresu). Jest to nieco inaczej niż w Javie, gdzie adresy (czy raczej odniesienia) mogły być argumentami wyłącznie operatorów porównania (' ==' i ' !='), ale nie operatorów relacyjnych. W C++ można porównywać adresy za pomocą operatorów relacyjnych pod warunkiem, że są to adresy elementów tej samej tablicy.
Wynikiem operacji jest wartość logiczna true lub false. Jak mówiliśmy (patrz rozdziału o typie logicznym ), wartości logiczne reprezentowane są w zasadzie przez wartości całkowite: wartość 0 jest równoważna false, a dowolna wartość niezerowa true. Obowiązuje to również dla wartości wskaźnikowych: wartość pusta (nullptr) jest interpretowana jako false, a każda inna jako true.
Operatory bitowe wymienione są w tabeli na pozycjach odpowiadających priorytetom 11 (przesunięcia bitowe), 8, 7 i 6. Argumentami muszą być wartości całkowite, wynik też jest typu całkowitego. Obowiązują przy tym normalne reguły konwersji argumentów do typu wspólnego.
Operatory bitowe nie „interesują” się wartościa liczbową argumentów, ale ich reprezentacją bitową. Przypomnijmy, że zwyczajowo numeruje się bity reprezentujące wartości zmiennych, poczynając od zera, od bitu najmniej znaczącego (odpowiadającego współczynnikowi przy zerowej potędze dwójki) do bitu najbardziej znaczącego. Reprezentując graficznie układ bitów, bit zerowy umieszcza się po prawej stronie, a bit najbardziej znaczący po lewej (patrz rozdział o typach całkowitych ).
Rozpatrzmy zatem bardziej szczegółowo działanie poszczególnych operatorów bitowych na wartości liczbowe. Jeden z nich — negacja bitowa — jest jednoargumentowy, pozostałe są dwuargumentowe.
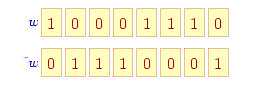
Operator bitowej negacji ('∼'), działając na wartość całkowitą zwraca nową wartość, w której wszystkie bity ulegają odwróceniu: tam, gdzie w argumencie był
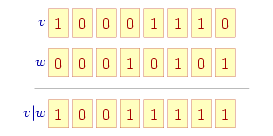
Alternatywa bitowa ('|') jest operatorem dwuargumentowym: dla kolejnych pozycji sprawdzane są pojedyncze bity w obu argumentach i obliczana ich suma logiczna: w wyniku bit na odpowiadającej pozycji jest jedynką (bit ustawiony), jeśli w którymkolwiek argumencie bit na tej pozycji był ustawiony, a zero, gdy w obu argumentach na tej pozycji również występowało zero (jak na rysunku poniżej).
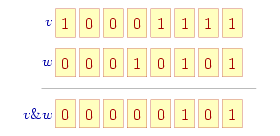
Koniunkcja bitowa ('&') jest też operatorem dwuargumentowym: dla kolejnych pozycji sprawdzane są pojedyncze bity w obu argumentach i obliczany ich iloczyn logiczny: w wyniku bit na odpowiadającej pozycji jest jedynką (bit ustawiony), jeśli w obu argumentach bit na tej pozycji był ustawiony, a zero, gdy w którymkolwiek z argumentów na tej pozycji występowało zero (patrz rysunek).
Jeśli stała określająca tryb nazywa się tryb, to maskowanie jej ze stałą 8 (= 23) odpowie na pytanie, czy bit in jest czy nie jest ustawiony. Reprezentacja 8 składa się z samych zer, z wyjątkiem pozycji trzeciej (czwarty bit od prawej), na której bit jest ustawiony. Zatem obliczając koniunkcję dostaniemy na wszystkich innych pozycjach na pewno zero, na pozycji czwartej zaś jedynkę, jeśli w tryb ten bit był ustawiony, a zero, jeśli nie był. Zatem wartość wyrażenia tryb & 8 będzie niezerowa wtedy i tylko wtedy, jeśli bit in był w zmiennej tryb ustawiony, niezależnie od stanu innych bitów w tej zmiennej.
Operator bitowej różnicy symetrycznej ('^') jest też operatorem dwuargumentowym: dla kolejnych pozycji sprawdzane są pojedyncze bity w obu argumentach i obliczana jest ich różnica symetryczna: wynikowy bit na odpowiadającej pozycji jest jedynką (bit ustawiony), jeśli w obu argumentach bity na tej pozycji były różne, a zerem jeśli w obu argumentach na tej pozycji występowały bity takie same — dwa zera albo dwie jedynki.
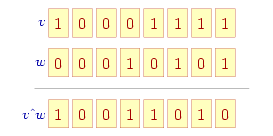
| b | m |
b |
(b |
| 1 | 1 | 0 | 1 |
| 1 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
| 0 | 0 | 0 | 0 |
Przesunięcia bitowe ('<<' i '>>') są operatorami dwuargumentowymi: lewy argument jest tu pewną wartością całkowitą na bitach której operacja jest przeprowadzana, prawy argument, również całkowity, określa wielkość przesunięcia. Wyobraźmy sobie, że lewy argument w ma układ bitów jak w górnej części rysunku. Przesunięcie w tej zmiennej bitów w lewo o dwa, 'w = w << 2', odpowiada przesunięciu wszystkich bitów o dwie pozycje w lewo (w kierunku pozycji bardziej znaczących). Bity „wychodzące” z lewej strony są tracone bezpowrotnie. Z prawej strony „wchodzą” bity zerowe. Tak więc po wykonaniu tej instrukcji reprezentacja zmiennej w będzie taka jak w środkowej części rysunku. Analogicznie, po przesunięciu teraz bitów w prawo o trzy pozycje ('w = w >> 3') otrzymamy reprezentację zmiennej w jak w dolnej części rysunku (pod pewnymi warunkami — patrz niżej).
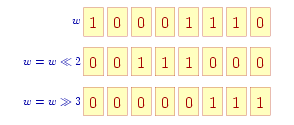
W C/C++ sprawa nie jest taka jasna. Istnieją tu specjalne typy bez znaku (unsigned), za to nie istnieje „potrójny” operator przesunięcia '>>>' w prawo.
Wobec tego w większości implementacji przyjęto następującą konwencję: jeśli typem wartości lewego argumentu jest typ bez znaku (unsigned), to przy przesuwaniu w prawo wchodzą z lewej strony bity zerowe; jeśli natomiast typem wartości lewego argumentu jest typ ze znakiem (signed), to przy przesuwaniu w prawo reprodukowany jest z lewej strony bit znaku, czyli skrajny lewy bit — jeśli było to zero, to zero, jeśli była to jedynka, to jedynka.
Prawy argument operatora przesunięcia, wskazujący na wielkość tego przesunieęcia, zawsze powinien być nieujemny i mniejszy od rozmiaru w bitach wartości, na której dokonujemy przesunięcia. W Javie jest dobrze określone przez specyfikację języka, co się dzieje, jeśli te warunki nie są spełnione; w C/C++ może to zależeć od implementacji i wobec tego lepiej takich konstrukcji unikać.
Na zakończenie rozpatrzmy przykład ilustrujący to, o czym
mówiliśmy na temat operacji bitowych.
1. #include <iostream>
2. using namespace std;
3.
4. void bitsChar(char k) {
5. int bits = 8*sizeof(k); ➊
6. unsigned char mask = 1<<(bits-1);
7. for (int i = 0; i < bits; i++) {
8. cout << (k & mask ? 1 : 0);
9. mask >>= 1; ➋
10. }
11. cout << endl;
12. }
13.
14. void bitsShort(short k) {
15. int bits = 8*sizeof(k);
16. unsigned short mask = 1<<(bits-1);
17. for (int i = 0; i < bits; i++) {
18. cout << (k & mask ? 1 : 0);
19. mask >>= 1;
20. }
21. cout << endl;
22. }
23.
24. void bitsInt(int k) {
25. int bits = 8*sizeof(k);
26. unsigned int mask = 1<<(bits-1);
27. for (int i = 0; i < bits; i++) {
28. cout << (k & mask ? 1 : 0);
29. mask >>= 1;
30. }
31. cout << endl;
32. }
33.
34. int main() {
35. short s = -1; int i = 259;
36.
37. cout << "char 'a' : "; bitsChar('a');
38. cout << "short -1 : "; bitsShort(s);
39. cout << "int 259 : "; bitsInt(i);
40. cout << endl;
41. cout << "ios::in : "; bitsInt(ios::in);
42. cout << "ios::out : "; bitsInt(ios::out);
43. cout << "ios::app : "; bitsInt(ios::app);
44. cout << "ios::in | ios::out\n ";
45. bitsInt(ios::in | ios::out);
46. }
Na początku tego programu definiujemy trzy niemal identyczne funkcje, których zadaniem jest wypisanie bitowej reprezentacji argumentu. Funkcje różnią się tylko typem argumentu: może nim być char, short lub int. W rozdziale o szablonach funkcji dowiemy się, jak można było uniknąć pisania trzech wersji tak podobnych funkcji.
Przyjrzyjmy się jednej z tych funkcji, na przykład funkcji bitsChar. W linii ➊ sprawdzamy, jaki jest rozmiar w bitach wartości argumentu k (tu oczywiście wiemy, że będzie to 8, bo sizeof(k) dla k typu char da jedynkę). Następnie tworzymy maskę mask typu unsigned char. Chodzi nam o to, aby długość maski była taka jak długość k, ale by była to zmienna na pewno bez znaku — w ten sposób przy przesuwaniu w prawo będą z lewej strony „wchodzić” zera. Maskę inicjujemy wartością '1 << 7' (bo bits wynosi 8). Reprezentacja jedynki to siedem bitów zerowych i jeden, prawy (czyli najmłodszy), bit ustawiony. Przesuwając ten układ bitów w lewo otrzymamy liczbę, której reprezentacją jest jedynka i siedem zer (jedynka tym razem z lewej strony). Robimy to po to, by pętla drukująca, która teraz następuje, przebiegała przez kolejne bity liczby k od lewej do prawej, a nie odwrotnie.
Następnie w pętli obliczamy koniunkcję bitową k z maską mask. Ponieważ maska ma tylko jeden bit ustawiony, w ten sposób sprawdzamy, czy odpowiedni bit jest też ustawiony w k. Jeśli tak, to wynikiem koniunkcji będzie jakaś wartość niezerowa, interpretowana jako true w pierwszym argumencie operatora selekcji, a zatem wartością tejże selekcji ' (k&mask ? 1 : 0)' będzie jedynka, która zostanie wypisana na ekranie. Jeśli w k odpowiedni bit nie jest ustawiony, wydrukowane zostanie zero.
W linii ➋ przesuwamy bity w masce o jeden w prawo. Ponieważ zadbaliśmy, aby maska była typu bez znaku, z lewej strony będą wchodzić same zera. Zatem w kolejnych przebiegach pętli maska cały czas będzie zawierać dokładnie jedną jedynkę, „wędrującą” od lewej do prawej. A więc w kolejnych przebiegach pętli sprawdzone i wydrukowane będą, w kolejności od lewej do prawej, wszystkie bity zmiennej k.
Podobnie działają pozostałe dwie funkcje: bitShort i bitInt — jedyna różnica to typ argumentu.
W programie głównym drukujemy reprezentację bitową kilku liczb całkowitych. Wyniki wyglądają następująco:
char 'a' : 01100001
short -1 : 1111111111111111
int 259 : 00000000000000000000000100000011
ios::in : 00000000000000000000000000001000
ios::out : 00000000000000000000000000010000
ios::app : 00000000000000000000000000000001
ios::in | ios::out
00000000000000000000000000011000
Widać, że (jak o tym mówiliśmy w
rozdziale o typach całkowitych ),
reprezentacją liczby -1 są jedynki na wszystkich bitach.
Znak 'a' odpowiada, jak łatwo policzyć, wartości
całkowitej
26 +25 + 1 = 64 + 32 + 1 = 97, co rzeczywiście
jest kodem ASCII litery 'a'.
Dalej ilustrujemy to, co mówiliśmy o stałych ios::in, ios::out itd. Widzimy, że są to pełne potęgi dwójki, a więc w ich reprezentacji bitowej występuje tylko jedna jedynka na odpowiedniej pozycji: w stałej ios::trunc na pozycji czwartej (licząc od zera), a w stałej ios::out na pozycji pierwszej. Obliczając ich alternatywę (sumę) bitową otrzymujemy liczbę, w której reprezentacji bitowej te i tylko te dwa bity są ustawione (ostatnia linia wydruku).
Argumentami operatorów logicznych
'
&&' (koniunkcja), '![]() ' (alternatywa)
i '
!' (negacja)
mogą być zarówno wartości typu
bool
jak i wartości całkowite;
w tym ostatnim przypadku wartości zostaną zinterpretowane według
normalnej zasady: 0
→
false,
niezero
→
true. Obliczona
wartość jest typu logicznego: alternatywa (suma logiczna) daje wynik
true
wtedy i tylko wtedy gdy choć jeden z argumentów ma
wartość
true, natomiast koniunkcja (iloczyn logiczny)
ma wartość
true
tylko jeśli oba argumenty są
true.
' (alternatywa)
i '
!' (negacja)
mogą być zarówno wartości typu
bool
jak i wartości całkowite;
w tym ostatnim przypadku wartości zostaną zinterpretowane według
normalnej zasady: 0
→
false,
niezero
→
true. Obliczona
wartość jest typu logicznego: alternatywa (suma logiczna) daje wynik
true
wtedy i tylko wtedy gdy choć jeden z argumentów ma
wartość
true, natomiast koniunkcja (iloczyn logiczny)
ma wartość
true
tylko jeśli oba argumenty są
true.
Koniunkcja i alternatywa są skrótowe. Oznacza to, że prawy argument nie jest w ogóle obliczany, jeśli po obliczeniu lewego wynik jest już przesądzony. Tak więc
Na przykład, jeśli a, b i r są zmiennymi typu całkowitego, to przypisanie
r = a && b;jest równoważne
if (a == 0)
r = 0;
else
{
if (b == 0) r = 0;
else r = 1;
}
a przypisanie
r = a || b;jest równoważne
if (a != 0)
r = 1;
else
{
if (b != 0) r = 1;
else r = 0;
}
Rozpatrzmy jeszcze jeden przykład ilustrujący skrótowość
dwuargumentowych operatorów logicznych:
1. #include <iostream>
2. using namespace std;
3.
4. bool fun(int k) {
5. k = k - 3;
6. cout << "Fun zwraca " << k << endl;
7. return k;
8. }
9.
10. int main() {
11. if ( fun(1) && fun(2) && fun(3) && fun(4) ) ➊
12. cout << "Koniunkcja true" << endl;
13. else
14. cout << "Koniunkcja false" << endl;
15.
16. if ( fun(1) || fun(2) || fun(3) || fun(4) ) ➋
17. cout << "Alternatywa true" << endl;
18. else
19. cout << "Alternatywa false" << endl;
20. }
W linii ➊ sprawdzany jest warunek w postaci koniunkcji wartości logicznych zwracanych przez funkcję fun (równie dobrze mogłyby to być wartości całkowite). Ponieważ fun(3) zwraca 0 czyli logiczne false, funkcja w ogóle nie zostanie już wywołana z argumentem 4, bo wynik już jest znany: wartością całego wyrażenia w nawiasie musi być false niezależnie od tego, co zwróciłaby funkcja fun dla argumentu 4. Widzimy to z wydruku
Fun zwraca -2
Fun zwraca -1
Fun zwraca 0
Koniunkcja false
Fun zwraca -2
Alternatywa true
Podobnie dla alternatywy w linii ➋. Już pierwsze wywołanie
funkcji
fun
dało wynik
true
(odpowiada to
niezerowej wartości zwracanej, w tym przypadku -2). Alternatywa
jest prawdziwa, gdy choć jeden argument jest
true, wobec tego
po wywołaniu
fun(1) wynik całego wyrażenia jest znany
(true) i wywołań
fun(2),
fun(3)
i
fun(4) nie będzie.
W grupie o priorytecie 2 wymienione są operatory zwykłego przypisania (' =') oraz złożone operatory przypisania.
Lewa strona przypisania musi być zawsze l-wartością. Tak więc
double x;
x + 2 = 7; // NIE
jest niepoprawne, natomiast
double x, *y = &x;
*(y + 2) = 7;
byłoby legalne (choć prawdopodobnie bez sensu), bo wyłuskanie
wartości daje w wyniku l-wartość.
Wykonanie przypisania polega na obliczeniu wartości prawej strony i umieszczeniu wyniku pod adresem l-wartości występującej po stronie lewej. Zauważmy asymetrię: prawa strona mówi co policzyć, lewa gdzie zapisać wynik.
Wartością i typem całego wyrażenia przypisania jest wartość i typ lewej strony po wykonaniu przypisania. Całe przypisanie jest l-wartością. Na przykład
int m = 1, n = 2;
(m=n) = 6;
cout << m << " " << n << endl;
drukuje '6 2'.
1. #include <iostream>
2. using namespace std;
3.
4. int main()
5. {
6. int k;
7. while ( (k = cin.get()) != '\n' )
8. cout << "Wprowadzono znak '" << (char)k
9. << ”, o kodzie ASCII " << k << endl;
10. }
w linii 7 przypisujemy do k wartośc znaku — czyli jego kod ASCII — odczytaną z klawiatury za pomocą metody get wywołanej na rzecz obiektu cin — patrz rozdział o operacjach we/wy . Całe przypisanie ' (k=cin.get())' ma wartość k po przypisaniu; tę wartość porównujemy z predefiniowaną stałą EOF, oznaczającą koniec strumienia danych. Zauważmy, że nawias wokół tego wyrażenia był konieczny, bowiem priorytet porównania, !=, jest wyższy niż priorytet operatora przypisania, a nam chodzi o to, aby najpierw dokonać przypisania, a dopiero jego wynik porównać z EOF. Przykładowe uruchomienie tego programu daje
cpp> g++ -pedantic-errors -Wall -o przypis przypis.cpp
cpp> ./przypis
Ala ma...[ENTER]
Wprowadzono znak 'A', o kodzie ASCII 65
Wprowadzono znak 'l', o kodzie ASCII 108
Wprowadzono znak 'a', o kodzie ASCII 97
Wprowadzono znak ' ', o kodzie ASCII 32
Wprowadzono znak 'm', o kodzie ASCII 109
Wprowadzono znak 'a', o kodzie ASCII 97
Wprowadzono znak '.', o kodzie ASCII 46
Wprowadzono znak '.', o kodzie ASCII 46
Wprowadzono znak '.', o kodzie ASCII 46
cpp>
Dzięki temu, że wartością całego wyrażenia z przypisaniem jest
wartość lewej strony po jego wykonaniu,
przypisania można stosować kaskadowo. Tak więc
int k = 7, j, m;
int n = m = j = k;
jest prawidłowe: ponieważ wiązanie operatora przypisania
jest od prawej, wartością wyrażenia '
m=j=k',
równoważnego '
m=(j=k)', jest wartość
m
po przypisaniu (czyli w naszym przypadku 7). Ta wartość zostanie
użyta do zainicjowania definiowanej zmiennej
n.
Efektem ubocznym będzie nadanie wartości również zmiennym
m
i
j. Zauważmy, że instrukcja byłaby
błędna, gdyby któraś ze zmiennych
m,
j,
k
nie była utworzona wcześniej.
Złożone operatory przypisania pozwalają na prostszy zapis niektórych przypisań: tych, w których ta sama l-wartość występuje po lewej i prawej stronie przypisania. Zamiast instrukcji
a = a @ b;gdzie symbol ” oznacza któryś z operatorów
| + | - | * | / | % |
| & | | |
a @= b;Drobna różnica, najczęściej bez znaczenia, pomiędzy tymi instrukcjami polega na tym, że w drugiej z nich wartość a jest obliczana jednokrotnie, a w pierwszej dwukrotnie. Zwykle druga z tych form, 'a = b', jest efektywniejsza.
Jako przykład zastosowania rozpatrzmy program:
1. #include <iostream>
2. using namespace std;
3.
4. void bitsInt(int k) {
5. unsigned int mask = 1<<31;
6. for (int i = 0; i < 32; i++, mask >>= 1) {
7. cout << (k & mask ? 1 : 0);
8. if (i%8 == 7) cout << " ";
9. }
10. cout << endl;
11. }
12.
13. int main() {
14. unsigned int k = 255<<24 | 153<<16 | 255<<8 | 255; ➊
15. cout << "k przed: "; bitsInt(k);
16. (k <<= 8) >>= 24; ➋
17. cout << "k po: "; bitsInt(k);
18. }
Funkcja bitsInt jest tu podobna do tej z programu bits.cpp — tak samo służy do drukowania bitowej reprezentacji liczby całkowitej. W tej wersji z góry założyliśmy, że typ int jest czterobajtowy. Prócz tego przesuwanie maski przenieśliśmy do części inkrementującej nagłówka pętli, umieszczając tam dwie instrukcje wyrażeniowe oddzielone przecinkiem (o operatorze przecinkowym — w jednym z następnych podrozdziałów ). Dodaliśmy też drukowanie spacji po każdej grupie ośmiu bitów, aby uczynić wydruk bardziej przejrzystym.
W linii ➊ konstruujemy liczbę o z góry zadanej reprezenatcji bitowej. Wyrażenie '255 << 24' daje liczbę z samymi jedynkami w najstarszym bajcie (255 to osiem jedynek, następnie przesunięte o 24 pozycje w lewo). Wyrażenie '153 << 16' to układ bajtów 10011001 przesunięty w lewo o 16 pozycji, czyli do bajtu trzeciego od lewej. Z kolei '255 << 8' daje osiem jedynek w bajcie drugim, a samo 255 — osiem jedynek w bajcie najmłodszym. Suma (alternatywa) bitowa „składa” wszystkie te bajty: otrzymujemy zatem liczbę o reprezentacji przedstawionej w pierwszej linii wydruku:
k przed: 11111111 10011001 11111111 11111111
k po: 00000000 00000000 00000000 10011001
Operator przypisania złożonego zastosowaliśmy w linii ➋.
Wyrażenie '(k <<= 8)' powoduje przesunięcie w zmiennej
k
wszystkich bitów w lewo o osiem pozycji. Zatem zawartość
bajtu najstarszego zostaje „zgubiona”, bajt 10011001
przechodzi na jego pozycję, a kolejne dwa, czyli pierwszy i drugi,
stają się drugim i trzecim (od lewej). Bajt najmłodszy wypełniany
jest zerami. Wynik całego wyrażenia jest l-wartością, a zatem ma sens
zastosowanie do niego następnego przypisania złożonego: tym razem
przesuwamy zawartość zmiennej
k
o 24 pozycje w prawo.
Ponieważ zmienna
k
jest bez znaku, z lewej strony
„wchodzą” same zera, a 24 najmłodsze bity „wychodzą” z prawej
strony. Układ bitów 10011001 po tej operacji znajduje się
na pozycji najmłodszego bajtu. W efekcie widzimy, że cała operacja
daje w efekcie liczbę równą tej, której reprezentacja binarna zawarta
była w trzecim od lewej bajcie wyjściowej liczby. W podobny sposób
moglibyśmy „wyciąć” zawartość pozostałych bajtów. Takie wycinanie
pojedynczych bajtów stosuje się na przykład przy kodowaniu trzech
(albo czterech) składowych koloru w jednej liczbie.
Operator warunkowy (selekcji) jest jedynym operatorem trzyargumentowym. Jego składnia:
b ? w1 : w2Najpierw obliczana jest wartość wyrażenia b i ewentualnie konwertowana do typu bool. Jeśli jest to true, obliczane jest wyrażenie w1, a wyrażenie w2 jest ignorowane. Wartością całego wyrażenia jest wartość w1. Jeśli jest to false, obliczane jest wyrażenie w2, a wyrażenie w1 jest ignorowane. Wartością całego wyrażenia jest wtedy wartość w2. Jeśli zarówno w1 i w2 są l-wartościami, to i wartość operatora warunkowego jest l-wartością.
Klasyczny przykład zastosowania operatora selekcji to implementacja funkcji max zwracającej większą z wartości swych argumentów:
int maxim(int a, int b) {
return a > b ? a : b;
}
Inny przykład zastosowania operatora selekcji podany zostanie w następnym podrozdziale.
Jako przedostatni w tabeli występuje operator zgłoszenia wyjątku throw: omówimy go w rozdziale o wyjątkach .
Operator przecinkowy jest dwuargumentowy: po dwóch stronach przecinka dwa wyrażenia
wyr1 , wyr2Działanie jego polega na:
Inny, nieco dziwaczny, przykład ilustruje program:
1. #include <iostream>
2. using namespace std;
3.
4. int main() {
5. int r = 0;
6. int k;
7.
8. while (cin >> k, k) { ➊
9. r += k > 0 ? (cout << "Dodatnia\n" , +1)
10. : (cout << "Ujemna\n" , -1);
11. }
12. cout << "Roznica ilosci dodatnich i ujemnych : "
13. << r << endl;
14. }
Operator przecinkowy jest tu użyty w linii ➊ w warunku pętli while. Mamy tu pierwsze wyrażenie, 'cin >> k', wczytujące kolejną daną z klawiatury, i drugie, po prostu k, dzięki któremu pętla skończy się, gdy wczytana zostanie liczba 0 (gdyż wartością całego wyrażenia przecinkowego jest wartość prawego argumentu). W pętli do r dodawana jest (operator złożonego przypisania) wartość nieco skomplikowanego wyrażenia. Jest to operator selekcji — patrz podrozdział o operatorze selekcji — sprawdzający znak k; w każdym przypadku rezultat będzie znów wartością wyrażenia przecinkowego. Dla k dodatnich będzie to wartość
(cout << "Dodatnia\n" , +1)czyli +1 z efektem ubocznym polegającym na wypisaniu słowa "Dodatnia". Analogicznie, dla k ujemnych od r odjęte zostanie 1, a jako efekt uboczny wypisane będzie słowo "Ujemna". Po wyjściu z pętli wypisywana jest różnica między ilością wczytanych liczb dodatnich i ujemnych. Na przykład wynik programu może być następujący:
cpp> przec
2
Dodatnia
6
Dodatnia
-3
Ujemna
6
Dodatnia
-1
Ujemna
3
Dodatnia
0
Roznica ilosci dodatnich i ujemnych : 2
cpp>
Niektóre operatory mają też formę czysto tekstową:
| tekstowa | symboliczna | tekstowa | symboliczna |
| and | && | and_eq | &= |
| bitand | & | bitor | | |
| compl | ∼ | not | ! |
| not_eq | != | or | |
| or_eq | |= | xor | ^ |
| xor_eq | ^= |
Forma tekstowa może być zamiennie stosowana z formą wyrażoną za pomocą symboli nieliterowych.
T.R. Werner, 21 lutego 2016; 20:17